Although remarkable progress has been made in recent years, current multi-exposure image fusion (MEF) research is still bounded by the lack of real ground truth, objective evaluation function, and robust fusion strategy.
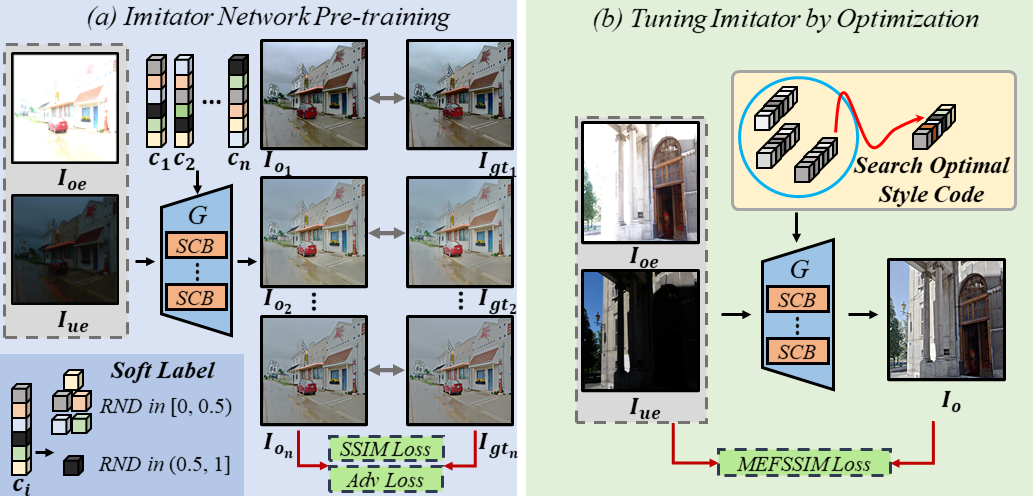
In this paper, we study the MEF problem from a new perspective. We don’t utilize any synthesized ground truth, design any loss function, or develop any fusion strategy. Our proposed method EMEF takes advantage of the wisdom of multiple imperfect MEF contributors including both conventional and deep learning-based methods. Specifically, EMEF consists of two main stages: pre-train an imitator network and tune the imitator in the runtime. In the first stage, we make a unified network imitate different MEF targets in a style modulation way. In the second stage, we tune the imitator network by optimizing the style code, in order to find an optimal fusion result for each input pair.
In the experiment, we construct EMEF from four state-of-the-art MEF methods and then make comparisons with the individuals and several other competitive methods on the latest released MEF benchmark dataset. The promising experimental results demonstrate that our ensemble framework can “get the best of all worlds”. The code is available at https://github.com/medalwill/EMEF.


@article{liu2023emef,
title={EMEF: Ensemble Multi-Exposure Image Fusion},
volume={37},
url={https://ojs.aaai.org/index.php/AAAI/article/view/25259},
DOI={10.1609/aaai.v37i2.25259},
number={2},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Liu, Renshuai and Li, Chengyang and Cao, Haitao and Zheng, Yinglin and Zeng, Ming and Cheng, Xuan},
year={2023},
month={Jun.},
pages={1710-1718}
}